在部署之前评估通用人工智能模型可靠性的新技术
基础模型是大规模深度学习模型,已在大量通用、未标记的数据上进行了预训练。它们可应用于各种任务,例如生成图像或回答客户问题。
但这些模型是 ChatGPT 和 DALL-E 等强大人工智能工具的支柱,它们可能会提供错误或误导性的信息。在安全攸关的情况下,例如行人接近自动驾驶汽车,这些错误可能会造成严重后果。
为了帮助防止此类错误,麻省理工学院和麻省理工学院-IBM Watson AI 实验室的研究人员开发了一种技术,用于在将基础模型部署到特定任务之前评估其可靠性。
他们通过训练一组彼此略有不同的基础模型来实现这一点。然后他们使用他们的算法来评估每个模型学习到的关于同一测试数据点的表示的一致性。如果表示一致,则意味着该模型是可靠的。
当他们将他们的技术与最先进的基线方法进行比较时,发现他们的技术在各种分类任务中能够更好地捕捉基础模型的可靠性。
有人可以使用这种技术来决定是否应在特定环境中应用模型,而无需在真实数据集上进行测试。当数据集可能因隐私问题而无法访问时,例如在医疗保健环境中,这可能特别有用。此外,该技术还可用于根据可靠性得分对模型进行排名,使用户能够选择最适合其任务的模型。
“所有模型都可能出错,但知道何时出错的模型更有用。量化这些基础模型的不确定性或可靠性的问题变得更加困难,因为它们的抽象表示难以比较。我们的方法可以让你量化表示模型对任何给定输入数据的可靠性,”资深作者 Navid Azizan 说,他是麻省理工学院机械工程系和数据、系统和社会研究所 (IDSS) 的 Esther and Harold E. Edgerton 助理教授,也是信息和决策系统实验室 (LIDS) 的成员。
与他一起撰写了一篇关于这项工作的论文的主要作者是 LIDS 研究生 Young-Jin Park、麻省理工学院-IBM Watson AI 实验室的研究科学家 Hao Wang 和 Netflix 高级研究科学家 Shervin Ardeshir。该论文将在 7 月 15 日至 19 日在巴塞罗那举行的人工智能不确定性会议 ( UAI 2024 ) 上发表,并在arXiv预印本服务器上提供。
计算共识
传统的机器学习模型经过训练可以执行特定任务。这些模型通常根据输入做出具体预测。例如,模型可能会告诉您某张图片中是否包含猫或狗。在这种情况下,评估可靠性可能只是查看最终预测以查看模型是否正确。
但基础模型则不同。该模型使用通用数据进行预训练,其创建者并不知道它将应用于哪些下游任务。用户在模型经过训练后,可将其调整到特定任务。
与传统的机器学习模型不同,基础模型不会给出“猫”或“狗”标签等具体输出。相反,它们会根据输入数据点生成抽象表示。
为了评估基础模型的可靠性,研究人员采用了集成方法,训练了几个具有许多共同属性但彼此略有不同的模型。
“我们的想法就像计算共识一样。如果所有这些基础模型都为我们数据集中的任何数据提供一致的表示,那么我们可以说这个模型是可靠的,”Park 说。
但他们遇到了一个问题:如何比较抽象的表现形式?
“这些模型只是输出一个由一些数字组成的向量,因此我们无法轻松地比较它们,”他补充道。
他们使用“邻里一致性”的思想解决了这个问题。
研究人员准备了一组可靠的参考点,用于在模型集合上进行测试。然后,针对每个模型,他们调查位于该模型测试点表示附近的参考点。
通过观察邻近点的一致性,他们可以估计模型的可靠性。
对齐表示
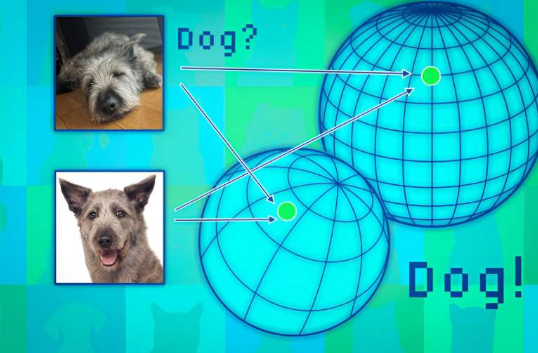
基础模型将数据点映射到所谓的表示空间中。可以将此空间视为一个球体。每个模型都将相似的数据点映射到其球体的同一部分,因此猫的图像放在一个地方,狗的图像放在另一个地方。
但是每个模型都会在自己的范围内以不同的方式映射动物,因此虽然猫可能被归类在一个范围的南极附近,但另一个模型可能会将猫映射到北半球的某个地方。
研究人员使用邻近点作为锚点来对齐这些球体,以便使这些表示具有可比性。如果某个数据点的邻居在多个表示中保持一致,那么人们应该对该点的模型输出的可靠性充满信心。
当他们在广泛的分类任务上测试这种方法时,他们发现它比基线更加一致。此外,它不会因具有挑战性的测试点而失败,而其他方法则不会。
此外,他们的方法可用于评估任何输入数据的可靠性,因此可以评估模型对特定类型的个体(例如具有某些特征的患者)的效果。
王说:“即使所有模型的整体表现都很平均,但从个人的角度来看,你还是会选择最适合自己的模型。”
然而,一个限制在于,他们必须训练一组大型基础模型,这在计算上非常昂贵。未来,他们计划找到更有效的方法来构建多个模型,或许可以通过对单个模型进行小幅扰动来实现。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【木地板材料】木地板是一种广泛应用于家居和商业空间的地面装饰材料,因其自然美观、耐用性强、环保性好等特...浏览全文>>
-
【木地板安装】木地板安装是一项需要细致规划和专业操作的工程,无论是新房装修还是旧房翻新,选择合适的木地...浏览全文>>
-
【木的组词怎么写】在汉语学习中,词语的积累和运用是非常重要的部分。对于“木”这个字来说,它不仅是常见的...浏览全文>>
-
【木的象形字有哪些字】在汉字的发展过程中,许多字最初都是通过象形的方式创造出来的,用来表示具体的事物。...浏览全文>>
-
【木岛法子介绍】木岛法子(Kazuko Kikuchi)是日本著名演员、模特及艺人,以其在影视作品中的出色表现和独特...浏览全文>>
-
【木代尔是什么面料】“木代尔是什么面料”是许多消费者在选购衣物时常常会提出的问题。木代尔是一种天然纤维...浏览全文>>
-
【木代尔和莫代尔哪种面料好】在选择衣物面料时,很多人会遇到“木代尔”和“莫代尔”这两个名称,容易混淆它...浏览全文>>
-
【萝卜的营养价值】萝卜是一种常见的根茎类蔬菜,不仅味道清脆爽口,还具有丰富的营养价值。无论是生吃、炒食...浏览全文>>
-
【萝卜的药用功效和作用】萝卜,作为日常生活中常见的蔬菜之一,不仅味道清脆、营养丰富,还具有多种药用价值...浏览全文>>
-
【萝卜的家常做法】萝卜是一种非常常见的蔬菜,不仅价格实惠,而且营养丰富,适合多种烹饪方式。无论是炖、炒...浏览全文>>