新方法使用生成人工智能来模仿人类运动
一个国际研究小组通过结合中央模式生成器(CPG)和深度强化学习(DRL),创建了一种模仿人体运动的新方法。该方法不仅模仿步行和跑步运动,而且还可以生成缺乏运动数据的频率的运动,实现从步行到跑步的平滑过渡运动,并允许适应具有不稳定表面的环境。
他们的突破细节于2024年4月15日发表在《IEEE机器人与自动化快报》杂志上。
我们可能不会想太多,但步行和跑步涉及固有的生物冗余,使我们能够适应环境或改变我们的步行/跑步速度。考虑到其复杂性,在机器人中再现这些类似人类的动作是众所周知的挑战。
当前的模型通常难以适应未知或具有挑战性的环境,这使得它们的效率和效果降低。这是因为人工智能适合生成一个或少量正确的解决方案。对于生物体及其运动,不只有一种正确的模式可供遵循。有一系列可能的运动,但并不总是清楚哪一种是最好或最有效的。
DRL是研究人员寻求克服这一问题的一种方法。DRL通过利用深度神经网络来处理更复杂的任务并直接从原始感官输入中学习,从而扩展了传统的强化学习,从而实现了更灵活、更强大的学习能力。它的缺点是探索广阔的输入空间需要巨大的计算成本,特别是当系统具有高自由度时。
另一种方法是模仿学习,其中机器人通过模仿人类执行相同运动任务的运动测量数据来学习。尽管模仿学习擅长在稳定的环境中学习,但在面对训练期间未遇到的新情况或环境时,它会遇到困难。它有效修改和导航的能力受到其学习行为范围狭窄的限制。
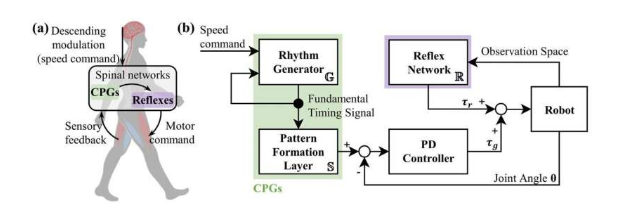
东北大学工程研究生院教授MitsuhiroHayashibe解释说:“我们通过将这两种方法结合起来,克服了它们的许多局限性。”“模仿学习被用来训练类似CPG的控制器,我们没有将深度学习应用于CPG本身,而是将其应用于支持CPG的反射神经网络形式。”
CPG是位于脊髓的神经回路,就像生物导体一样,产生肌肉活动的节律模式。在动物中,反射回路与CPG协同工作,提供足够的反馈,使它们能够调整速度和行走/跑步动作以适应地形。
自适应模仿CPG(AI-CPG)方法通过采用CPG及其自反对应物的结构,在模仿人体运动的同时,在运动生成方面实现了显着的适应性和稳定性。
Hayashibe补充道:“这一突破为机器人技术中生成类人运动树立了新的基准,具有前所未有的环境适应能力。我们的方法代表了机器人控制生成人工智能技术的发展向前迈出了重要一步,具有跨行业的潜在应用”。
该研究小组由东北大学工程研究生院和洛桑联邦理工学院或洛桑瑞士联邦理工学院的成员组成。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【木地板材料】木地板是一种广泛应用于家居和商业空间的地面装饰材料,因其自然美观、耐用性强、环保性好等特...浏览全文>>
-
【木地板安装】木地板安装是一项需要细致规划和专业操作的工程,无论是新房装修还是旧房翻新,选择合适的木地...浏览全文>>
-
【木的组词怎么写】在汉语学习中,词语的积累和运用是非常重要的部分。对于“木”这个字来说,它不仅是常见的...浏览全文>>
-
【木的象形字有哪些字】在汉字的发展过程中,许多字最初都是通过象形的方式创造出来的,用来表示具体的事物。...浏览全文>>
-
【木岛法子介绍】木岛法子(Kazuko Kikuchi)是日本著名演员、模特及艺人,以其在影视作品中的出色表现和独特...浏览全文>>
-
【木代尔是什么面料】“木代尔是什么面料”是许多消费者在选购衣物时常常会提出的问题。木代尔是一种天然纤维...浏览全文>>
-
【木代尔和莫代尔哪种面料好】在选择衣物面料时,很多人会遇到“木代尔”和“莫代尔”这两个名称,容易混淆它...浏览全文>>
-
【萝卜的营养价值】萝卜是一种常见的根茎类蔬菜,不仅味道清脆爽口,还具有丰富的营养价值。无论是生吃、炒食...浏览全文>>
-
【萝卜的药用功效和作用】萝卜,作为日常生活中常见的蔬菜之一,不仅味道清脆、营养丰富,还具有多种药用价值...浏览全文>>
-
【萝卜的家常做法】萝卜是一种非常常见的蔬菜,不仅价格实惠,而且营养丰富,适合多种烹饪方式。无论是炖、炒...浏览全文>>