研究表明使用人数越多的语言往往更难被机器学习
就在几个月前,很多人还无法想象基于人工智能的“语言模型”能够如此出色地模仿人类语音。ChatGPT编写的内容通常与人类生成的文本难以区分。
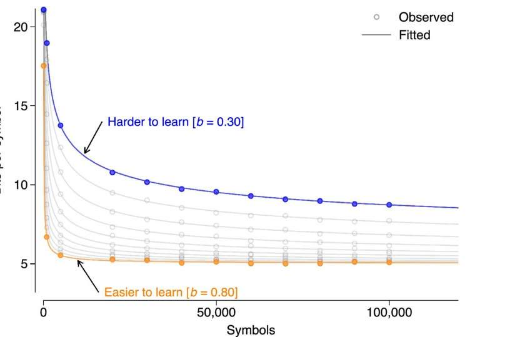
德国曼海姆莱布尼茨德语研究所(IDS)的一个研究小组现已使用1,293种不同语言的文本材料来研究不同计算机语言模型学习“书写”的速度。令人惊讶的结果是:对于算法来说,由很多人使用的语言往往比语言社区较小的语言更难学习。该研究发表在《科学报告》杂志上。
语言模型是可以处理和生成人类语言的计算机算法。语言模型可以识别大量文本数据中的模式和规律,从而逐渐学习预测未来的文本。一种特殊的语言模型是所谓的“Transformer”模型,著名的聊天机器人服务ChatGPT就是在该模型上构建的。
当算法输入人类生成的文本时,它会了解单词成分、单词和短语在特定上下文中出现的概率。然后使用学到的知识进行预测,即在新情况下生成新文本。
例如,当模型分析句子“在黑夜里我听到远处……”时,它可以预测“嚎叫”或“噪音”等词将是适当的延续。该预测基于对语言中的语义关系和单词组合概率的一些“理解”。
在一项新研究中,IDS的语言学家团队通过使用1,293种语言的文本材料对计算机语言模型进行训练,研究了计算机语言模型学会预测的速度。该团队使用了较旧且不太复杂的语言模型以及现代变体,例如上面提到的Transformer模型。他们研究了不同的算法需要多长时间才能理解不同语言的模式。
研究发现,算法为了学习一种语言(即预测接下来的内容)需要处理的文本量因语言而异。事实证明,语言算法学习母语较多的语言往往比学习母语较少的语言更困难。
然而,事情并不像听起来那么简单。为了验证学习难度和说话者人数之间的关系,必须控制几个因素。
挑战在于,密切相关的语言(例如德语和瑞典语)比相关性较远的语言(例如德语和泰语)更加相似。然而,需要控制的不仅是语言之间的相关程度,还需要控制其他影响,例如两种语言之间的地理接近程度或用于培训的文本材料的质量。
“在我们的研究中,我们使用了应用统计学和机器学习等多种方法来尽可能严格地控制潜在的混杂因素,”该研究的两位作者之一SaschaWolfer解释道。
然而,无论使用何种方法和输入文本类型,机器学习能力和说话者群体规模之间都存在稳定的统计相关性。
该研究的主要作者亚历山大·科普莱尼格(AlexanderKoplenig)表示:“结果确实让我们感到惊讶;根据目前的研究状况,我们原本的预期是相反的:使用人数较多的语言往往更容易让机器学习。”。
这种关系的原因迄今为止只能推测。例如,由同一研究小组领导的一项早期研究表明,较大的语言总体上往往更加复杂。因此,对于人类语言学习者来说,增加的学习努力也许会“得到回报”:因为一旦你学会了一种复杂的语言,你就有了更多不同的语言选择,这可能会让你以更短的形式表达相同的内容。
但需要更多的研究来检验这些(或其他解释)。“我们相对而言还处于起步阶段,”科普莱尼格指出。“下一步是找出我们的机器学习成果是否以及在多大程度上可以转移到人类语言习得中。”
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【木地板材料】木地板是一种广泛应用于家居和商业空间的地面装饰材料,因其自然美观、耐用性强、环保性好等特...浏览全文>>
-
【木地板安装】木地板安装是一项需要细致规划和专业操作的工程,无论是新房装修还是旧房翻新,选择合适的木地...浏览全文>>
-
【木的组词怎么写】在汉语学习中,词语的积累和运用是非常重要的部分。对于“木”这个字来说,它不仅是常见的...浏览全文>>
-
【木的象形字有哪些字】在汉字的发展过程中,许多字最初都是通过象形的方式创造出来的,用来表示具体的事物。...浏览全文>>
-
【木岛法子介绍】木岛法子(Kazuko Kikuchi)是日本著名演员、模特及艺人,以其在影视作品中的出色表现和独特...浏览全文>>
-
【木代尔是什么面料】“木代尔是什么面料”是许多消费者在选购衣物时常常会提出的问题。木代尔是一种天然纤维...浏览全文>>
-
【木代尔和莫代尔哪种面料好】在选择衣物面料时,很多人会遇到“木代尔”和“莫代尔”这两个名称,容易混淆它...浏览全文>>
-
【萝卜的营养价值】萝卜是一种常见的根茎类蔬菜,不仅味道清脆爽口,还具有丰富的营养价值。无论是生吃、炒食...浏览全文>>
-
【萝卜的药用功效和作用】萝卜,作为日常生活中常见的蔬菜之一,不仅味道清脆、营养丰富,还具有多种药用价值...浏览全文>>
-
【萝卜的家常做法】萝卜是一种非常常见的蔬菜,不仅价格实惠,而且营养丰富,适合多种烹饪方式。无论是炖、炒...浏览全文>>